AKS Known Issues
Known issues encountered during AKS cluster upgrade or rebuild
If a cluster is in a failed state and even after troubleshooting you are unable to complete the cluster upgrade before the auto-shutdown of AKS clusters, please delete the AKS cluster in a failed state manually within the portal and try again the following morning. This stops active jobs and pods on the failed cluster trying to reach inactive endpoints due to the healthy cluster being shutdown.
Upgrade failed in the portal
If the upgrade is showing as failed in the portal, you need to restart it by running a command on the cluster you are trying to upgrade. You can find the full resource ID in the portal too.
az resource update --ids <aks-resource-id>
One or more nodes has failed to upgrade
You can track the progress of the upgrade by running
kubectl get nodes
Eventually all nodes will show as running the intended version, in some cases however, one or more nodes may be stuck on the old AKS version, which will block the upgrade. This happens when a given node is unable to be drained before an upgrade, the most likely cause of which is a broken application.
To diagnose why a node has failed to upgrade, head to the AKS cluster in the Azure portal. Navigate to Node Pools > Linux/System/Other > Nodes > Stuck Node Name > Events. From here you will likely see a failed eviction and a reason why - after which you can troubleshoot further with the relevant team / application to unblock the node draining process. If the cluster is in a failed state, or no longer shows as updating in the portal, you will need to hit the update button again.
Quota limit reached
You may encounter a quota limit during an AKS upgrade due to the provisioning of new nodes during the process. Generally, you can increase these quotas yourself in the portal - by selecting the subscription that the AKS cluster is part of, and increasing the Compute quota to the recommended level.
DaemonSet Failed Scheduling
For a DaemonSet application (e.g. CSI driver, Oneagent or Kured), when applying an update or patch which requires a restart, a pod on a specific node may fail scheduling and blocks the rolling update from proceeding with restarting other pods.
An error similar to the below may be seen in the cluster events log:

- This happens when there is a capacity issue on specific cluster nodes
- DaemonSet rolling update is blocked with the pod stuck in
Pendingstate Deleting the pod does not fix issue as pod restarts and goes into same
PendingstateRun
kubectl get pod <pod name> -o yaml | grep nodeNameto identify the node where pod scheduling has failedRun
kubectl get pods -A | grep <node name>to list all pods running on nodeIdentify and delete one or more non-DaemonSet pods to restart on a different node and free up a capacity on the current node
If deleted pods are stuck in
Terminatingstate, usekubectl delete pod <pod name> --grace-period 0 --forceto forcefully delete podConfirm DaemonSet pod now starts successfully
Helm Release fails due to outdated chart
We recently encountered an issue while trying to deploy KEDA to the Crime AKS clusters. The helm release deployed fine on lower environments but threw errors when we went to roll it out to PRX and other Live environments.
Below is an example of the type of error thrown:
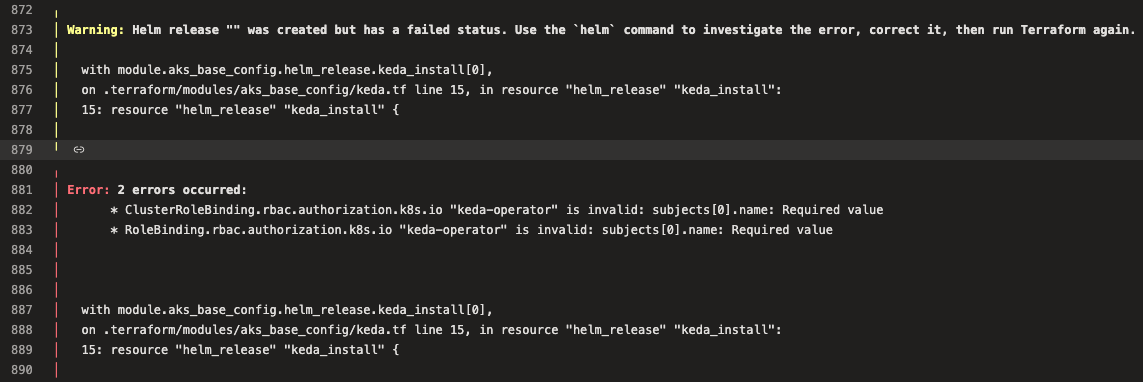
To troubleshoot the issue, you’ll first need to pull the chart locally.
To get the chart to your local machine, run helm registry login and sign in with credentials that have the acrPull permissions. In this case, we used the same creds that were being used in cpp-terraform-azurerm-aks-config.
helm registry login ${ACR_NAME} \
--username ${USERNAME} \
--password ${PASSWORD}
NOTE: If pulling from crmpdrepo01, you’ll need to ssh into the jumpbox as public network access is disabled.
Once logged in, you should be able to run helm pull to pull a copy of the chart to your local machine
helm pull oci://${ACR_NAME}/charts/${CHART} --version ${VERSION}
This should pull a .tgz archive containing the chart. Extract it using the tar command. You can now compare it against the same chart defined in cpp-helm-chart
In this instance, the issue ended up being that the KEDA chart stored in crmpdrepo01 contained templates that were no longer in the chart definition.
Here’s the contents of templates in the chart definition vs what was stored in crmpdrepo01
| Chart Definition | Live Chart in crmpdrepo01 |
|---|---|
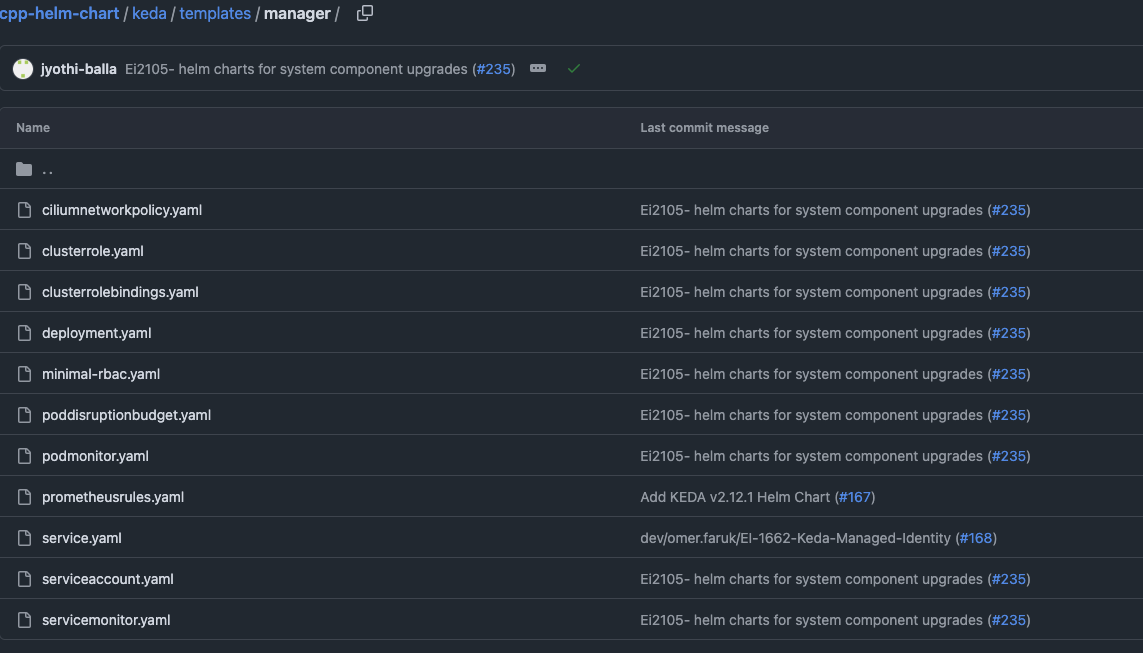 |
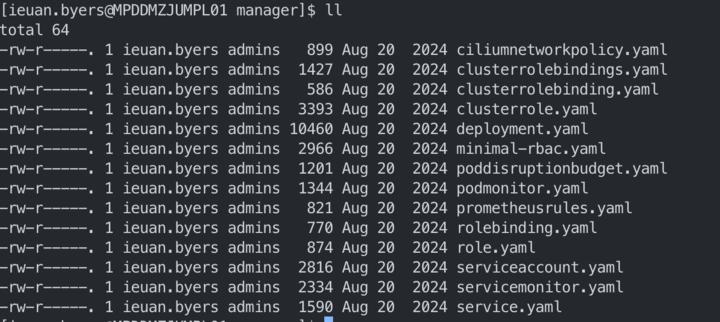 |
We’re not entirely sure how the chart in crmpdrepo01 became out of sync but one to watch out for in future.