Alfresco Deployments
This page contains information on how deployments of Alfresco are made in the most generic sense, there may be caveats and additional information on a per environment basis that is not yet known.
Deployments of Alfresco are carried out using the following YAML pipeline.
The Azure DevOps job for this is found here.
This pipeline is used to deploy the Alfresco Content Services Helm chart to a specific environment and namespace with optional inputs to control the pipeline and deployment all of which are detailed in this page.
!! Be aware that CCM deployments in AKS are cleared down at 10pm each evening
Helm Chart
Alfresco deployments are all made using the Helm charts stored in CPP.
There are currently 2 versions of the charts, one is for the current Production deployemnt and one is for the upcoming upgrade work
The current chart is heavily modified and is not a fork of any existing Alfresco chart.
The upgraded chart is mostly in line with Alfresco’s own chart for v6.0.2. This includes the compatible versions of additional services.
There are a number of customised templates within this new chart all of which came from the original chart and have been updated to suit the newer version of the chart. These are all prefixed with cpp_ naming convention to make it easier to know which will not be modified by future chart updates.
This is a complete list of the current custom templates in the chart:
- cpp_config-db-setup.yaml
- cpp_config-image-magick-overrides.yaml
- cpp_config-serviceaccounts.yaml
- cpp_dbsetup.yaml
- cpp_deployment-repository.yaml
- cpp_istio-policies.yaml
- cpp_secret-aca-license.yaml
- cpp_secret-acs-license.yaml
- cpp_secret-repo-jtoolopt.yml
- cpp_virtual-service.yaml
This template is an updated version of the one included in the official chart and any updates from a newer official chart would require these to be compared and the customisations ported into the newer version:
- cpp_deployment-repository.yaml
Repository
Alfresco Deploy Repository: link
Within the repository there are a number of folders/files:
azure-pipeline-variables- stores variable templates for live and non-live use. These are ingested in the main pipeline file.helm_secrets- an yaml file referenced within Ansible and contains a template module task to convert a template file to a populated yaml values file.- note: there appears to be no reference to this within the rest of the repository
plugins- contains Ansible plugin files (python) which can be used to extend the capabilities of Ansible when official modules do not exist.- This is referenced within the ansible.cfg file as the plugins directory allowed Ansible to use the them as modules
template.yml- the top main Ansible Playbook that the pipeline uses to convert the templates shown above into useful yaml values files for the Helm deployment.ansible.cfg- A simple config file that can be used to configure how Ansible runs, this contains only a reference to the plugins directory meaning Ansible will run a vanilla configuration during the pipeline.azure-pipelines.yaml- the main pipeline file responsible for deploying everything in the repository and detailed in the next sectionvalues- contains environment specific sub-folders and top-level templates or environment files used by the main pipeline.common.yml- a helm values file containing references for specific services within the deployment e.g. repository references for images or resources (cpu/mem) for AKS config.chart-versions.env- discussed as part of the YAML pipeline section, this contains key:value entries used by the pipelinealfweb_policies.yaml.j2and alfapp_policies.yaml.j2 - Jinja template files that Ansible will use as inputs and replace any instances of curly braces {{ }} with real values supplied at runtime.- Environment specific folders
values.j2- Every folder contains a values.j2 file for that environment which for Ansible to use as input for templating in pipeline provided values.chart-versions.env- Some files contains and environment level chart-versions file, this will override the top-level file with new environment specific valuesPRXandDEVcontain a number of additional values files for additional services. Each of the files are Jinja templates that Ansible will use to populate values at runtime IF certain pipeline parameters match expected values e.g. deployCdes = truealfresco-frontend-services- We’ve been told this is not used.alfresco-search- Alfresco 7.2 utilised Solr built into Alfresco Content Services (ACS), Afresco 7.4 and later use a sub-chart for Alfresco-search-services so this file may become relevant.cdes-content-services- We’ve been told this is not used and was part of a next phase that never materialised.
YAML Pipeline
Templates
The YAML pipeline ingests another repository for templates:
yaml
resources:
repositories:
- repository: cppAzureDevOpsTemplates
type: github
name: hmcts/cpp-azure-devops-templates
ref: "main"
endpoint: "hmcts"
Only one of the stages/jobs makes use of this:
- template: steps/common/precommit.yaml@cppAzureDevOpsTemplates
Parameters
- environment - a predefined list of environment names to choose from
- cluster - a predefined list of AKS clusters to choose from
- stack - a blank parameter that much be supplied in free text form
- platform - Live or Non Live choice
- agentPool - a radio button list to choose which agent pool is used for this specific run of the pipeline
- deleteNs - a boolean input to choose whether the Kubernetes namespace should be deleted before deployment i.e. delete and allow Helm to recreate it at deployment time
- deployCdes - a boolean input to choose whether you want to deploy CDES(Court Documents Evidence Sharing) component
- enableDebug - a true/false radio button input that sets system.debug variable to the chosen value.
Variables
- acrName - a conditional choice based on parameter values, if the parameter platform is nonlive then choose one value, if live choose another.
- system.debug - set to the value of the enabledDebug parameter and will enable detailed logging if true, more information here.
- template file - A template file is ingested as variables based on the value of the platform parameters. If Live or Nonlive it will pick the relevant file found here.
- The files contain environment specific connection or credential information e.g. service connection name.
Stages
The pipeline contains only 2 stages with the second stage doing the majority of the work.
Stage: Precommit
A single job stage that uses a template from the ingested repository for pre-commit checks found in this template and only runs during Pull Requests.
The pre-commit config can be found in the repo here and carries out the following checks, more information is available here:
- check-merge-conflict
- end-of-file-fixer
- detect-private-key
- check-case-conflict
- check-json
- trailing-whitespace
- sort-simple-yaml
- mixed-line-ending
Stage: DeployToCluster
This is the primary stage that carries out the deployment work for the pipeline, it contains a single job with multiple tasks.
This stage will only run if the build reason is manual.
A number of variable groups are ingested in this stage which are based on the values taken from the variable template file detailed previously.
variables:
- group: ${{ variables.vaultAdminCredentialsVarGroup }}
- group: ${{ variables.spnCredentialsVarGroup }}
Job: DeployToClusterJob
Step 1: ‘Calculate Variables’
An inline script is run that sets variables for the rest of the pipeline:
- Adds build tags to the build based on the values of the stack and environment parameters
- sets a stackNumber bash variable based on information taken from the stack parameter, uses sed to pull out a number from the input string.
- sets stackNumber as a pipeline variable based on the bash variable of the same name.
- sets a namespace bash variable based on the environment name and stack name:
ns-${{ parameters.environment }}-alfapp-$stackNumber - sets namespace as a pipeline variable based on the bash variable of the same name.
- sets a alfWebNamespace bash variable based on the environment name and stack name:
ns-${{ parameters.environment }}-alfweb-$stackNumber - sets alfWebNamespace as a pipeline variable based on the bash variable of the same name
Step 2: ‘Delete Namespace’
Another inline script that only runs when the parameter deleteNS is set to true.
- The script sets a finalStack bash variable based on parameter inputs for environment and stack.
- An if/else statement then runs to check which the values of the parameter environment and the finalStack bash variable to decide the value of a - vaultEnv bash variable.
- The value for vaultEnv is then used by the vault command to read in the value of a specific variable, in this case it is the kube config for the - cluster chosen at runtime.
- File permissions are changed and some outputs are set for the remainder of the script using set.
- The final steps are kubectl commands which delete the namespaces set in the calculate variables step.
A number of environment variables have been set for this job which appear to configure how Vault should operate.
The VAULT_ADDR and VAULT_TOKEN values come from an Azure DevOps variable group which is set on the stage detailed previously.
VAULT_ADDR: $(VAULT_ADDR)
VAULT_TOKEN: $(VAULT_TOKEN)
VAULT_SKIP_VERIFY: 1
VAULT_CAHOSTVERIFY: 0
KUBECONFIG: "/tmp/kubeconfig"
Step 3: ‘Deploy Alfresco to Cluster’
The final and most important step within the pipeline is an inline bash script.
- A number of parameters and variables are echoed to the pipeline log output in Azure DevOps
- The script sets a finalStack bash variable based on parameter inputs for environment and stack.
- An if/else statement then runs to check which the values of the parameter environment and the finalStack bash variable to decide the value of a - vaultEnv bash variable.
- The value for vaultEnv is then used by the vault command to read in the value of a specific variable, in this case it is the kube config for the - cluster chosen at runtime.
- File permissions are changed and some outputs are set for the remainder of the script using set.
Ansible playbook is run with this template.yml file which is a standard ansible playbook which uses the template module to populate prebuilt templates with input values based on the inputs from the pipeline
ansible-playbook template.yml -e env=${{ parameters.environment }} -e stack=${{ parameters.environment }}${{ parameters.stack }} -e stack_number=$(stackNumber) -e cdes=${{ parameters.deployCdes }}
As can be seen above, there are a number of input variables being defined for Ansible based on the parameters from the pipeline or variables in the script.
The following is a sample of the module tasks found within that ansible template.yml playbook
- name: Template values file
template:
src: "{{ playbook_dir }}/values/{{env}}/values.j2"
dest: "{{ playbook_dir }}/{{ env }}-values.yml"
Based on this task, this file is picked up by Ansible and any values with double curly braces e.g.{{ stack }} will be replaced with inputs from the ansible-playbook command in the pipeline
e.g. the {{ stack }} value in the template will be replaced with the value input to the variable here:
-e stack=${{ parameters.environment }}${{ parameters.stack }}
- A chart-versions environment file is sourced by default in the pipeline, setting a number of variables and values.“
- A chart-versions environment file is sourced if it exists for the environment chosen in the environment input which will override the values set in the default chart-versions.env file
At this point the script has setup a number of variables and configs ready for the actual deployment.
- Log into Azure Container Registry using Helm login command
- Pull the ccm-namespace chart from the repository:
$ACR_NAME/charts/ccm-namespace:$ccm_namespace_chart_version - Export the chart to the local install folder
- Pull the alfresco content services chart from the repository:
$ACR_NAME/charts/alfresco-content-services:$alfresco_content_services_chart_version - Export the chart to the local install folder
- An if statement then chooses which set of commands to run based on the value of the
deployCdesparameter.- If true additional charts are pulled for Alfresco Search and Alfresco Frontend services (We have been told these are no deployed!)
- If false Helm upgrade commands are executed which install the already pulled
ccm-namespaceandalfresco-content-servicesHelm charts
- A number of values files and inline values are set during the Helm upgrade commands based on the parameters in the pipeline.
A number of environment variables have been set for this job which appear to configure how Vault should operate.
The VAULT_ADDR and VAULT_TOKEN values come from an Azure DevOps variable group which is set on the stage detailed previously.
VAULT_ADDR: $(VAULT_ADDR)
VAULT_TOKEN: $(VAULT_TOKEN)
VAULT_SKIP_VERIFY: 1
VAULT_CAHOSTVERIFY: 0
ACR_NAME: ${{ variables.acrName }}
HELM_EXPERIMENTAL_OCI: 1
KUBECONFIG: "/tmp/kubeconfig"
Azure DevOps
The pipeline itself cant be found here.
The pipeline has a number of input parameters, some pre-populated with values from the YAML file and some are free text that must be entered (required).
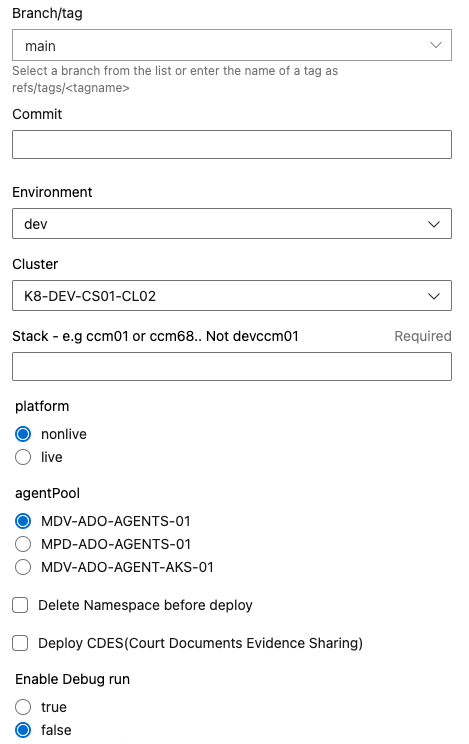
There are examples, such as this one, showing that the pipeline can be run from a PR to deploy to a specific environment which means we should be able to make any changes we want in a PR and deploy that version into an environment for testing purposes.
Expected inputs based on deploying to an STE environment:
Branch- PR/Branch name for the testCommit- blankEnvironment- STECluster- K8-DEV-CS01-CL01Stack- CCM89 based on the environment assigned to Yellow on this page: EA Environment managementPlatform- nonliveagentPool- MDV-ADO-AGENTS-01deleteNs- falsedeployCdes- falseenableDebug- false
These settings should enable you to deploy a full stack of Alfresco services into the AKS cluster under the namespace: ns-ste-alfapp-89
Remember that the branch created in the repository will have to contain specific inputs for us to be able to deploy an updated version of Alfresco:
- Namely the image tags will need to use the latest versions
- A chart-versions file may be required in the env folder if we have updated the main chart version.