Alfresco Updates
When upgrading Alfresco there are custom changes to be made beyond simply updating the chart and image versions.
Helm
There are a number of customised templates within this new chart all of which came from the original chart and have been updated to suit the newer version of the chart. These are all prefixed with cpp_ naming convention to make it easier to know which will not be modified by future chart updates.
This is a complete list of the current custom templates in the chart:
- cpp_config-db-setup.yaml
- cpp_config-image-magick-overrides.yaml
- cpp_config-serviceaccounts.yaml
- cpp_dbsetup.yaml
- cpp_deployment-repository.yaml
- cpp_istio-policies.yaml
- cpp_secret-aca-license.yaml
- cpp_secret-acs-license.yaml
- cpp_secret-repo-jtoolopt.yml
- cpp_virtual-service.yaml
This template is an updated version of the one included in the official chart and any updates from a newer official chart would require these to be compared and the customisations ported into the newer version:
- cpp_deployment-repository.yaml
When updating the chart, the official chart version will be determined by the Alfresco Content Services version being upgraded to.
The easiest way to see this is to select a repo tag version:
Then check the chart.yaml file to find the appVersion, this will show you the version of Alfresco Content Services (ACS) that this chart is compatible with. This is important because all sub-charts/dependencies and image versions will also be aligned with this version of the service.
Alfresco provide documentation for the Helm chart which can be found here. This section contains useful information on upgrading versions, major changes that have taken place and other useful information.
Its important to read this section before starting any update to the Helm chart
The process to bring the Helm chart back in line with the official chart was somewhat laborious and required using diff to compare the current and new versions. This proved to be useful as diff allows you to use side by side output and can be used recursively on sub-folders.
Download both the current chart and new chart and run diff with the less or more options to allowing paging through the output:
diff -rb --side-by-side <Current Helm Chart> <New Helm Chart> | less
This command will compare the new SDK folder to the existing repository and show output side by side in the terminal so you can compare.
-rmeans recursive so it will scan and check each sub-folder-bignores whitespace so it doe not flag a difference because of this
Note: The use of less removes coloured output, if you want to use this you can do the diff on each file and drop less from the command.
Within the output the following can be seen:
|- means that there is a difference on the line somewhere>- means the line only exists in the right side file (which ever file was second in the command)<- means the line only exists in the left side file
In some cases you will also see that files exist in only one of the folders. If they are in the new folder only they are either sample files that have been removed from the project folder or new files required for the SDK update. You’ll need to check each to see which outcome it is.
This process is mostly used to compare the built in templates and the values.yaml file used by the charts.
Image versions
As well as the value and template file differences, the images of each sub-service within the chart will have been updated. Alfreso provide upgrade documentation.
Updating the images in the values.yaml file to match those as defaults is recommended.
Image Storage
Whilst the image tags should match those in the supported platforms section of the Alfresco Documentation, the location of the images i.e. the repo we download from, will always be an ACR within the CPP tenancy.
There is a non-live an live ACR and the images stored within can be custom images built for CPP or cached versions of upstream images such as those we need for Alfresco.
The images pulled and then pushed to ACR can be found here.
The file is used by this pipeline to pull the images from the remote registry/repo:tag combination and pushed to ACR (always the nonlive and a flag exists to push to live as well). Note that in the file, multiple tags can be pulled from the remote registry allowing for upgrade testing.
- registry: quay.io
repo: alfresco/alfresco-content-repository
promote_live: yes
username: "<USERNAME>"
password_path: "secret/mgmt/<PASSWORD>"
tags:
- "7.2.0"
This pipeline is used only for images not built or maintained by CPP and in some cases the images are pulled from a private registry where credentials are required. If you are adding a new tag then this shouldnt matter but if you are adding a new image from a new registry please be mindful of this.
Alfresco Content Services container image
Also known as dr-alfresco-store or dr-store within CPP, this image is a customised version of the official Alfresco Content Services Repository image typically referenced in the official Helm chart.
This is image is built from the following Gerrit repo: dr-alfresco-store The master branch holds out of date information and code, only the dockerfile is up to date for the current Live deployment.
The Jar file referenced in that Dockerfile is not built from the master branch, it is built from the sdk4 branch which contains the code built and used in current Live deployment.
A new sdk4_6 was created to facilitate the upgrade to Alfresco 7.4.2 and is in testing. This branch also contains a full guide on local development and image build for this service and should be referenced for this purpose (note you must complete the Crime onboarding to access the Gerrit server).
All artifacts for the Alfresco service that are created get stored in Artifactory and the current Jar file can be found here.
Deployment
Deployment of the new Helm chart and image can be carried out using the guidance in alfresco deployment.
This should be deployed only to an STE stack that has been assigned for the upgrade and is not currently in used by anyone else.
Checking Alfresco
You can check Alfresco has deployed an updated version by accessing the service, this is only possible via Port-Forwarding as there is no external frontend for the service.
To port-forward to Alfresco you can run a kubectl command against the Alfresco Content Services Repository pod e.g.
kubectl port-forward pods/alfresco-content-services-alfresco-cs-repository 8080:8080 -n ns-ste-alfapp-89
format:
kubectl port-forward pods/<pod name> <pod port>:<local port> -n <namespace>
Once started you can then navigate to your web browser and access the service on http://localhost:8080 which should show you an Alfresco landing page.
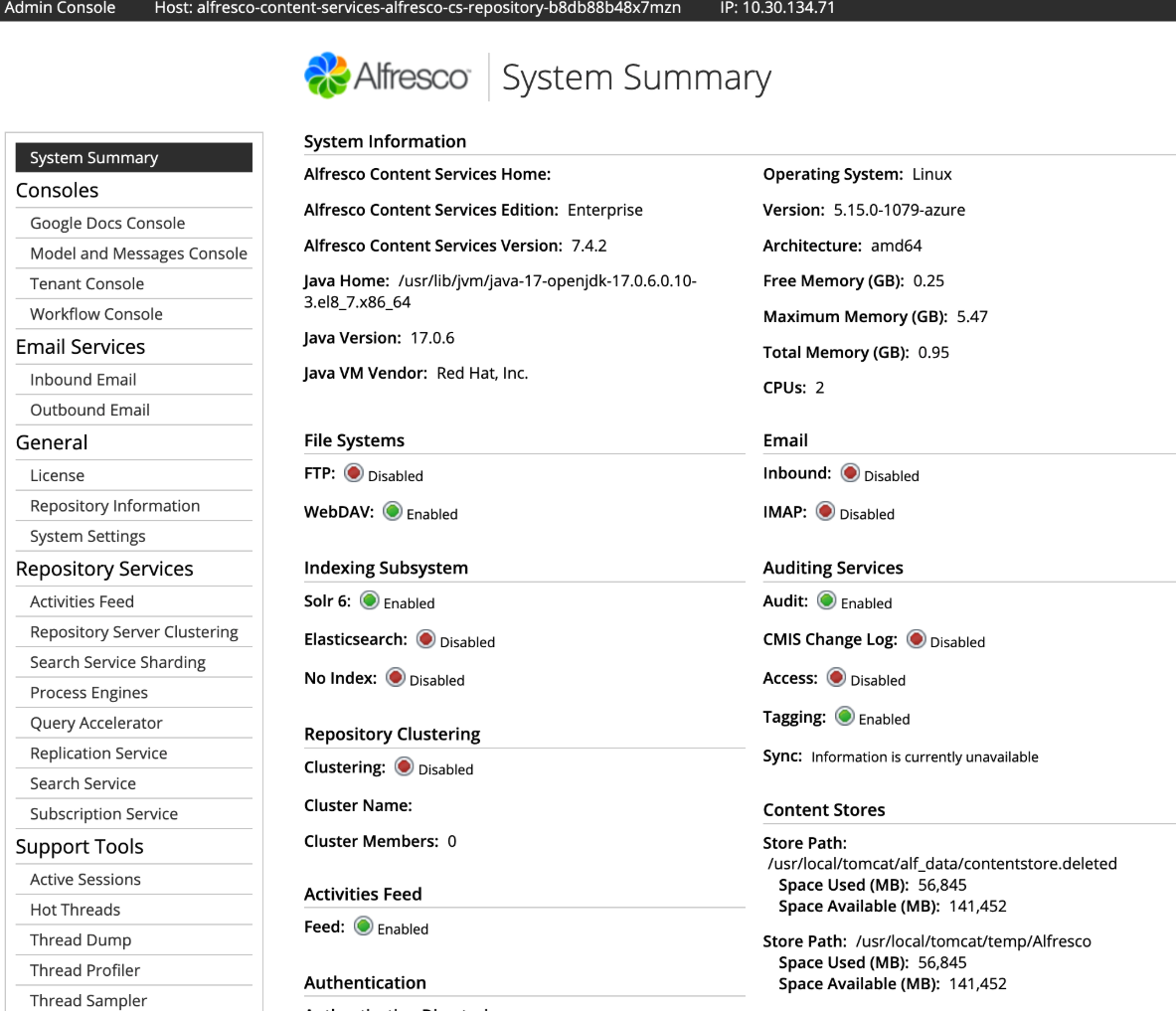
Selecting admin console on this page will prompt for credentials which by default are admin:admin. This will then load a page like this which contains versions, modules installed and settings:
Testing
Testing of the deployment requires additional components including additional services and test data.
Additional services
These deployments can be carried out via the CPP-AKS-DEPLOY pipeline and the following guide.
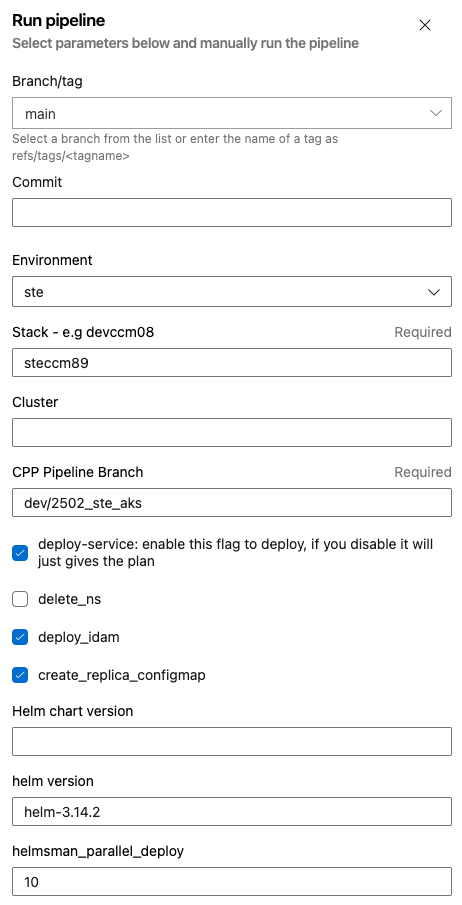
Example inputs of a successful deployment to an STE stack containing Alfresco:
Please note the guide is not completely up to date and contains old links:
- 1- Run the AKS deployment job to create new STE stack using below Jenkins job with below parameters This section references an old pipeline, the new pipeline is CPP-AKS-DEPLOY linked above
- 2- Run AKS alfresco job to create for new STE stack created above using below jenkins job with below parameters This section references an old pipeline, the new pipeline is CPP-Alfresco-Deploy linked in the alfresco deployment document.
The CPP Pipeline branch should match what is used in Production, the screenshot shows what was current at the time and the branch naming convention. You will need to ask around to find out what is currently deployed to Production and use that branch before a QA runs any tests.
Priming Data
Once deployed, the services/stack need to be primed with data to make the testing accurate and like for like.
This yaml pipeline is used for the priming pipeline. This ADO pipeline is used for deployment.
Please read through this guide for more information on Priming.
This pipeline can be used to restore PRIMING data or SIT data and the chosen option will depend on what the QA needs for testing purposes.
Example inputs:
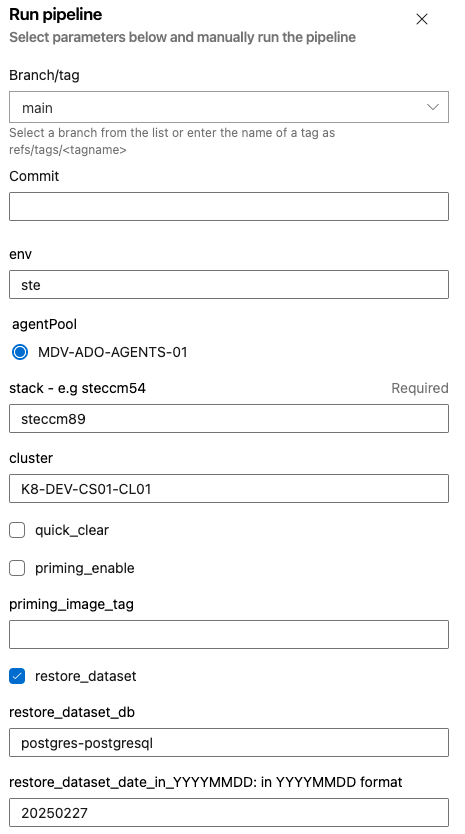
These inputs were used to restore SIT data to the STECCM89 stack, in this case you can see the restore_dataset option is selected and not priming_enable.
Completion
This setup was enough for a QA to carry out testing on the STE stack and other than re-deploying one of the pipelines shown there was no requirement for other setup during the testing phase.