Database schema changes
See Flyway database migration for automatically running schema changes via pipeline.
Adopting a Continuous Delivery (CD) pipeline and zero-downtime deployments brings challenges, particularly regarding evolution of underlying database schemas.
From Chapter 12 Managing Data, Continuous Delivery [David Farley; Jez Humble]:
The lifecycle of application data differs from that of other parts of the system. Application data needs to be preserved—indeed, data usually outlasts the applications that were used to create and access it. Crucially, data needs to be preserved and migrated during new deployments or rollbacks of a system. In most cases, when we deploy new code, we can erase the previous version and wholly replace it with a new copy. In this way we can be certain of our starting position. While that option is possible for data in a few limited cases, for most real-world systems this approach is impossible. Once a system has been released into production, the data associated with it will grow, and it will have significant value in its own right. Indeed, arguably it is the most valuable part of your system. This presents problems when we need to modify either the structure or the content. The underlying problem here is that we can’t just swap a new version of the database for an old version, like we would with blue/green deployments for code, if the data in question is constantly in motion.
What is zero-downtime deployment?
First, we need to define what zero-downtime actually means. Does it just apply to frontend services? Is it just public-facing frontend services? To perform zero-downtime deployments of frontend applications there are two options:
- If possible, decouple frontend and backend so that frontend still provides a useful service if one of the backends is down
- Decouple database schema changes from backend deployment and perform changes in multiple, backward-compatible steps
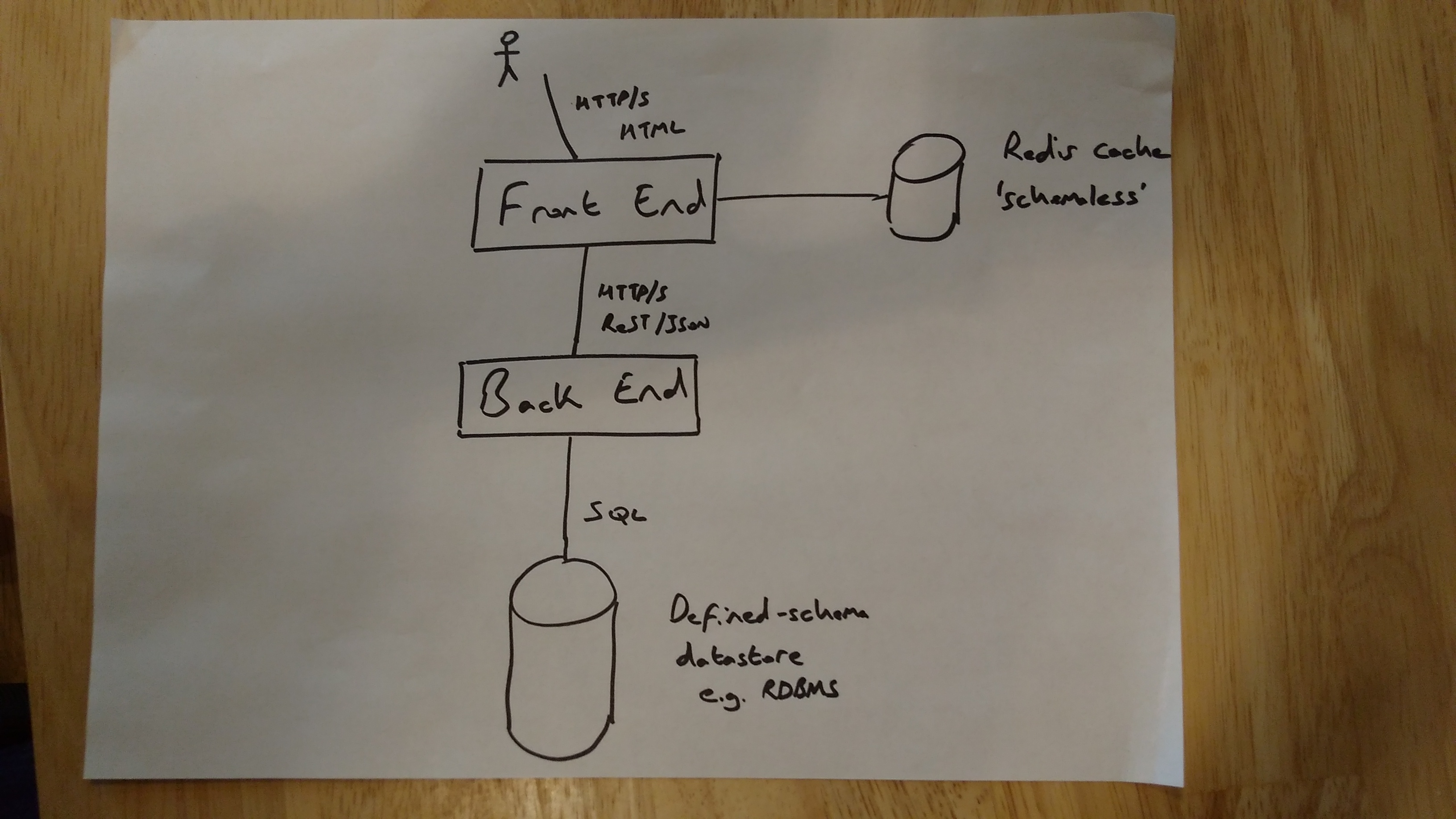
Can the frontend tolerate downtime of backend services? Can the frontend offer reduced functionality when backends are down but still provide a useful service to users? Is the backend ‘private’ so that it is only accessible to frontend services? If so, then it is possible to perform zero-downtime deploys by taking the backend services down for a short time to perform DB upgrades. This enables ‘traditional’ database migration deployments. Note, however, that if a backend doesn’t support zero-downtime deployments then it must be clearly documented so that any new consuming service knows to be appropriately decoupled.
If the frontend doesn’t function without the backend or the ‘backend’ is also a public-facing service (API) then the backend must also support zero-downtime deployments. If the backend is backed by a defined-schema datastore e.g. an RDBMS then extra steps need to be added to the release pipeline in order to facilitate this.
Zero-downtime database deployments
To perform zero-downtime database deployments the schema migration MUST be separated from the code deployment. Database Migrations Done Right explains further and gives an example of the steps required when adding a non-nullable column to an existing table. Essentially, database migrations must be performed in such a way that they are done independently of application deployments.
The underlying principle to obey here is:
Every change you make must be backward compatible with the rest of the system
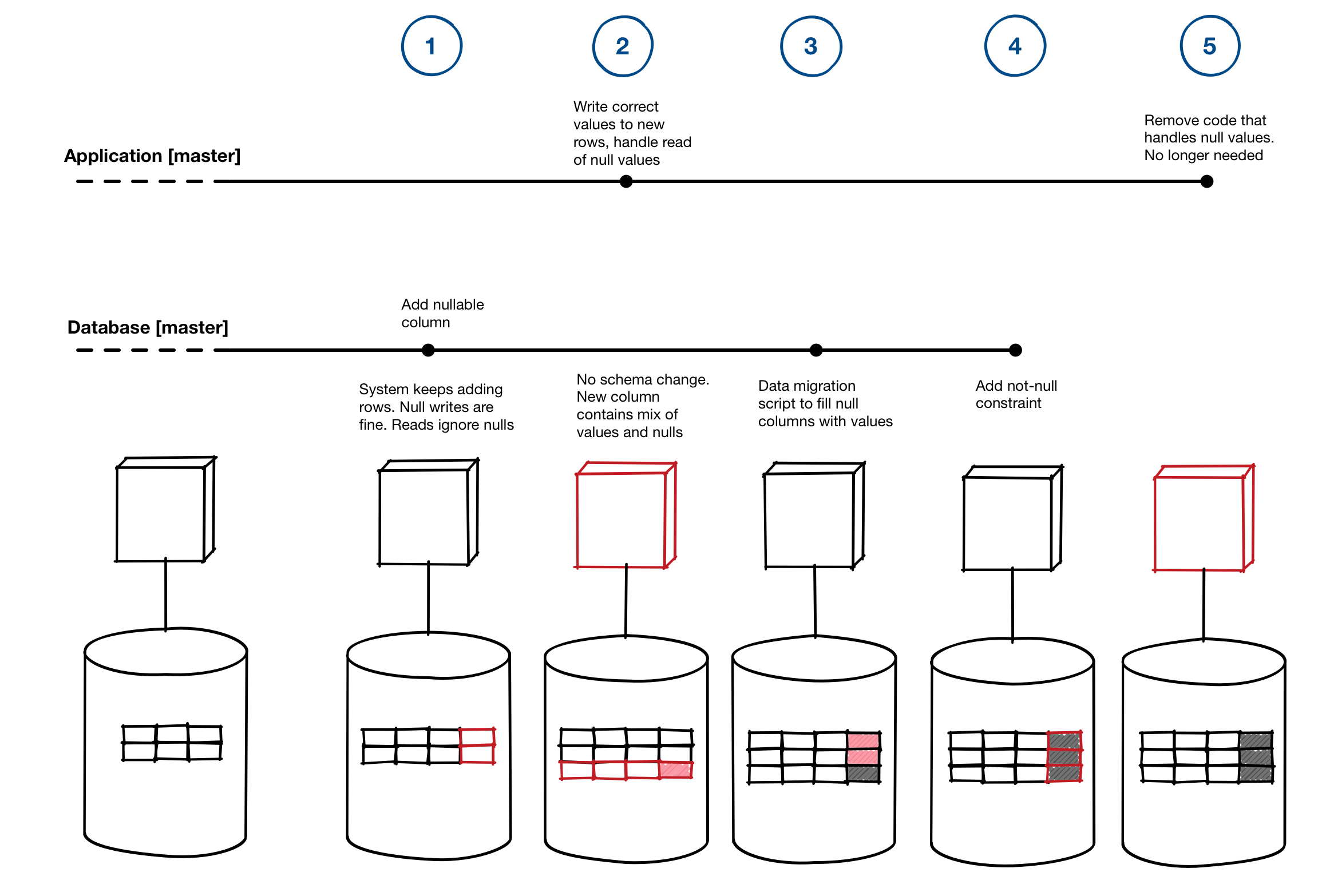
For the add non-nullable column scenario these are the backward compatible steps to perform the change:
- Add nullable column to database – System keeps adding rows, nulls are fine, reads ignore the null
- Code change to write correct value to new rows, and handle reading unexpected nulls – Database doesn’t change, now we have some null rows and some rows with data
- Run data migration to fill the other columns – This might be a script, or a bit of code in the application, either way your app doesn’t care about any row, it handles data and nulls just fine
- Add the non-null constraint – The database now has no nulls and your new code is writing the correct data.
- Remove the code that handles the null case – it won’t happen anymore.
Strategies for refactoring databases
These 2 articles give some ideas on what to do and what to avoid when refactoring your database on production systems:
PostgreSQL schema-change gotchas
Database schema changes without downtime
Here are some strategies on how to break down large database changes into less risky steps:
- Smaller changes are easier to apply
- Uniquely identify individual refactorings
- Implement a large change by many small ones
- Have a database configuration table
- Prefer triggers over views or batch synchronization
- Choose a sufficient deprecation period
- Simplify your database change control board strategy
- Simplify negotiations with other teams
- Encapsulate database access
- Be able to easily set up a database environment
- Do not duplicate SQL
- Put database assets under change control
- Beware of politics